URL (Web Scraping)
Web Scraping is used to bring data directly into Explorazor to perform analysis and generate insights.
To fetch data from the internet you can use a URL connector to web scrape a website.
- Go to Datasets / Add New / Fetch Data from URL
- Enter a Source Name for the data being retrieved, a name for the dataset to be uploaded on Explorazor
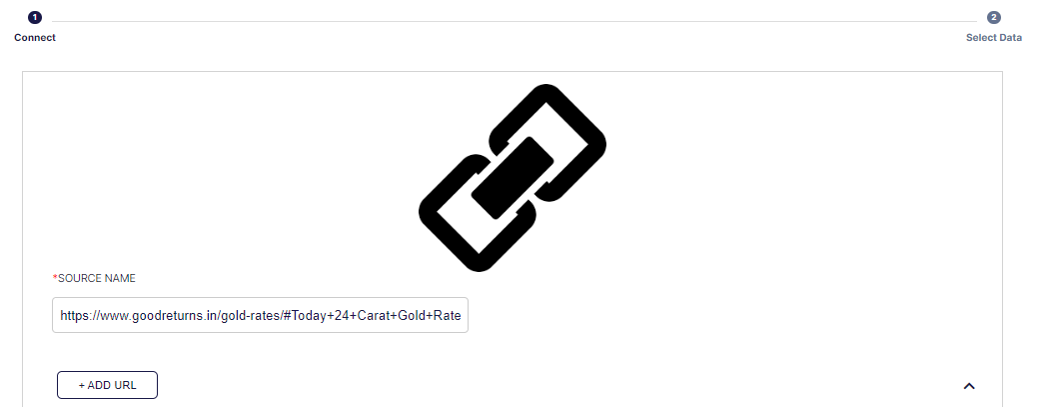
- Click ADD URL Enter values of the variables required to scrape data from the source website
- Name - A unique name for the Table
- URL - Website URL
- xPath - Location with information (table) on the webpage / full XPath
- Header-Index - Default (0)
- Skip-Begin - Default (1) To skip the Header
- Skip-End - Default (0)
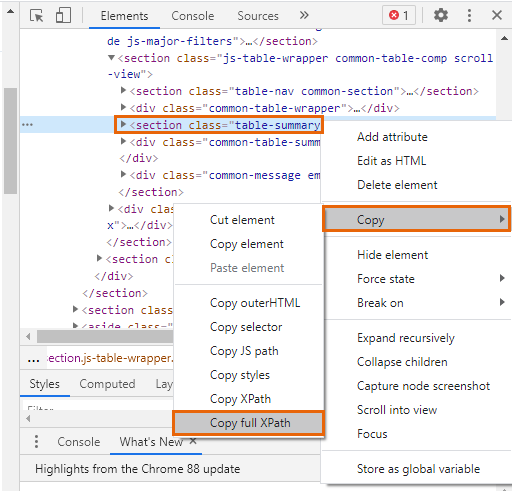
To locate the xPath value -
Right click on the webpage and click Inspect
In the window that opens up locate table-summary, right click on it and then click on Copy and Copy full xPath
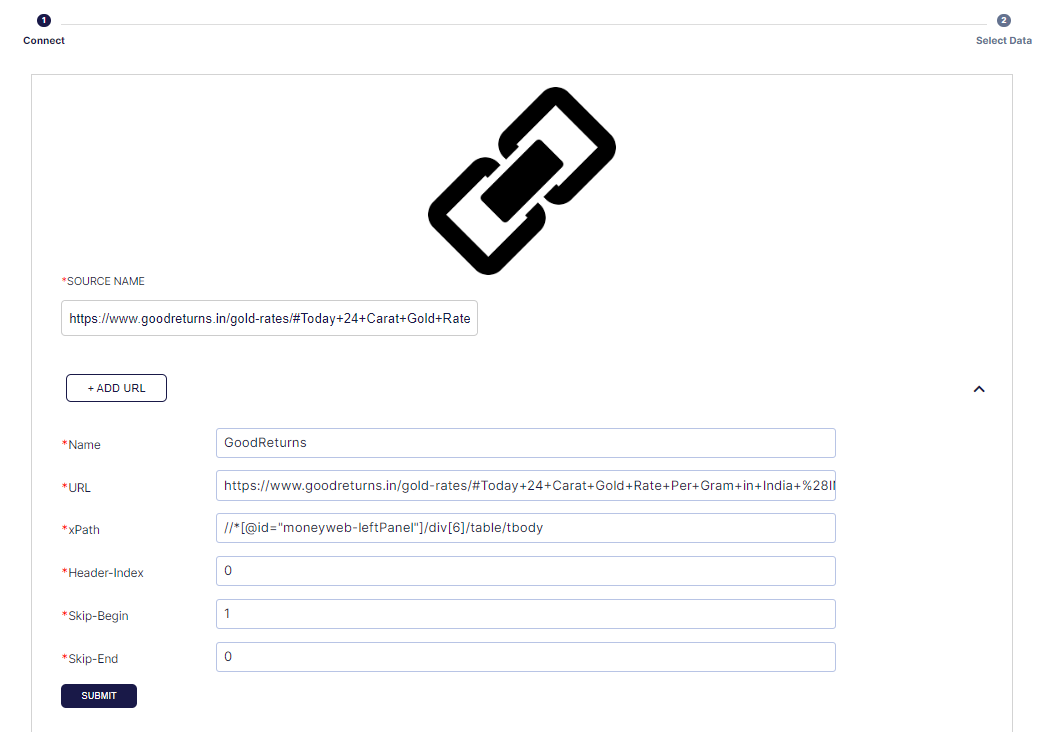
- Click Submit The table will be added.
- Click View tables
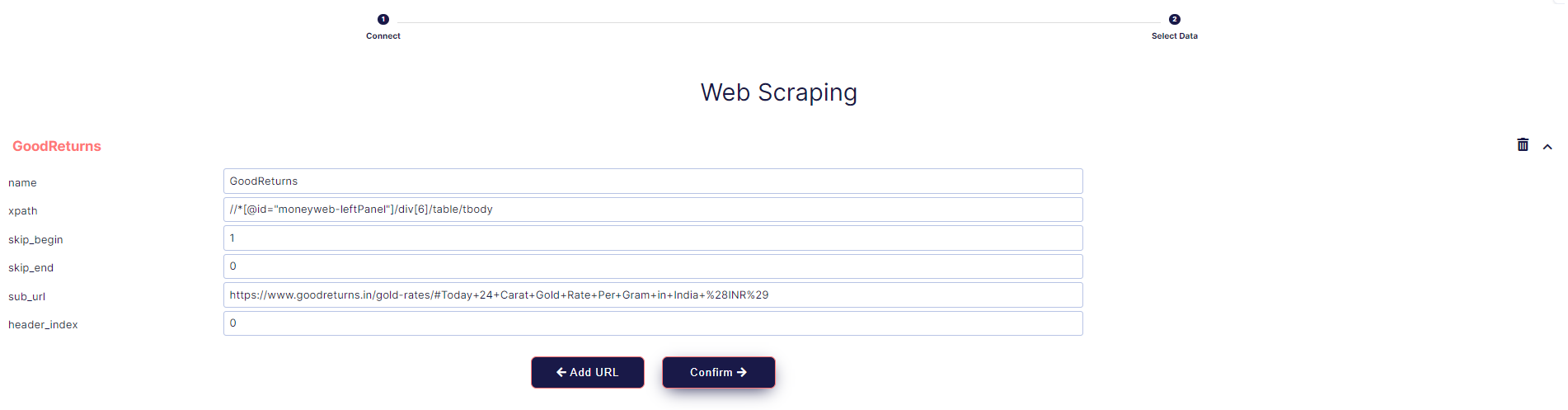
- In the Web Scraping screen click Confirm to submit the table
- The saved Data source appears under Datasets
